![[sql] user session diff](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fsm2FI%2FbtsF2Fg0V8m%2FZpgFOef6ekEySFZIeDeKa0%2Fimg.png)
서비스를 활성화 시키기위해 신규 유저를 유입시키는것은 중요하다. 그리고 신규 유저가 유입했다면 유저의 첫방문 이후 두번째 방문, 세번째 방문을 만들어내는것이 필요하다. 더불어 방문간의 시간차를 줄일수 있다면 더욱 좋겠다. 이런 맥락에서 우리는 이번시간에 유저의 첫 방문(session)에서 두번째 방문까지 걸린 시간을 구해보고자 한다.
순서는 아래와 같이 진행한다.
① 각 세션 발생 순서대로 넘버링 부여
② 두번째 세션이 존재하는 유저만 필터후, 유저별 두번째 세션과 첫번쨰 세션의 시간차 집계
③ 시간 차이에 대한 분포 테이블 생성
① 먼저, 유저의 첫 방문(session)에서 두번째 방문까지 걸린 시간을 계산하기 위해서는 유저별 세션 발생 순서를 구분해줘야하고, 두번째 세션을 만든 유저만 필터링해야한다.
이 두가지는 모두 window 함수로 구해주면된다. 유저별로 partiton by 를 해주면 각 유저별 세션 순서와 각 유저별 총 세션 갯수를 구해줄수 있다. 참고로, ga_sess 테이블에서는 session 데이터가 고유한 행으로 존재하기 때문에 count(*)를 사용했다.
select user_id, visit_stime
, row_number() over(partition by user_id order by visit_stime asc) as sess_rnum
, count(*) over(partition by user_id) as sess_cnt
from ga_sess
;
위 쿼리를 실행하면 아래처럼 유저별 세션 발생 순서와, 세션 총수를 구할수 있다.

② 이제 위 테이블에서 두번째 세션이 존재하는 유저만 거른후, 두번째 세션 시간과 첫번째 세션시간의 차이를 구해줘야한다. where 절에서 sess_cnt(세션 총 갯수)가 1을 초과하는 데이터만 가져오고, 동시에 sess_rnum(세션 넘버링)이 2 이하인 데이터만 필터링한다.
그 후에 유저별로 max(visit_stime), min(visit_stime)으로 집계해주면 각각 2번째 세션 생성시간과 1번째 세션 생성 시간을 각각 구할수 있다. 2번째 세션이 존재하는 유저만 필터링한 동시에, 각 유저별로 첫번째와 두번째 세션 데이터만 필터했기 때문이다.
이 두 값의 차이를 계산해주면 유저별 두번째 세션과 첫번째 세션의 시간차를 집계할 수 있다.
select user_id
, max(visit_stime) as max_time
, min(visit_stime) as min_time
, max(visit_stime) - min(visit_stime) as time_diff
from temp_01
where sess_rnum <= 2 and sess_cnt > 1
group by 1
;
아래 테이블을 확인해보면 첫번째 세션만 존재했던 U0000001 ~ U0000005 데이터는 모두 필터됐음을 확인할 수 있다.

③ 마지막으로 위 테이블을 이용해, 시간차이에 대한 분포를 한눈에 확인하고자 분포 테이블을 만들어주겠다. 분포테이블에는 시간차이에 대한 평균, 최소값, 최대값, 그리고 4분위수를 구한다.
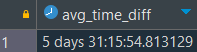
이때 평균값을 구할때는 avg(time_dff) 가 아닌, justify_interval(avg(time_dff))을 사용한다. avg(time_dff)를 사용하게되면 아래처럼 시간이 31시간으로 출력되게되며, 이는 인지하기에 적절하지 않은 형태다. 이런 경우 justify_interval(avg(time_dff)) 를 사용해주면 시간이 다시 24시간 단위로 집계되게 된다.

그리고 4분위수를 구할때는 within group 이라는 함수를 사용해야한다. 이 함수는 데이터가 정렬된 상태에서 집계함수가 적용될 수 있도록 도와준다. 우리는 time_diff(시간 차이)칼럼이 오름차순으로 정렬된 상태에서 각각 4분위수를 구해야하므로 within group 함수를 사용해서 시간차이 크기순으로 오름차순 정렬후에, 각각 지표를 구해준다.
▼ 위 두부분을 적용한 쿼리는 아래와 같다.
select justify_interval(avg(time_diff)) as avg_time_diff
, min(time_diff) as min_time_diff
, max(time_diff) as max_time_diff
, percentile_disc(0.25) within group(order by time_diff asc) as percentile_25
, percentile_disc(0.50) within group(order by time_diff asc) as percentile_50
, percentile_disc(0.75) within group(order by time_diff asc) as percentile_75
from temp_02
where time_diff::interval > interval '0 second'
;
①, ②, ③ 을 모두 적용한 최종적인 쿼리는 아래와 같다.
with
temp_01 as (
select user_id, visit_stime
, row_number() over(partition by user_id order by visit_stime asc) as sess_rnum
, count(*) over(partition by user_id) as sess_cnt
from ga_sess
),
temp_02 as (
select user_id
-- , max(visit_stime) as max_time
-- , min(visit_stime) as min_time
, max(visit_stime) - min(visit_stime) as time_diff
from temp_01
where sess_rnum <= 2 and sess_cnt > 1
group by 1
)
select justify_interval(avg(time_diff)) as avg_time_diff
, min(time_diff) as min_time_diff
, max(time_diff) as max_time_diff
, percentile_disc(0.25) within group(order by time_diff asc) as percentile_25
, percentile_disc(0.50) within group(order by time_diff asc) as percentile_50
, percentile_disc(0.75) within group(order by time_diff asc) as percentile_75
from temp_02
where time_diff::interval > interval '0 second'
;
위 쿼리를 적용하면 최종적으로 아래와같이 유저의 첫 방문(session)에서 두번째 방문까지 걸린 시간의 분포 테이블을 출력할 수 있다.
아래 테이블에서 평균 시간을보면 6일 7시간으로 재접속까지 시간이 꽤 오래 걸린다고 생각할수있다. 그러나 중앙값(50분위)를 보면 21시간으로, 평균에 비해 매우 짧은 시간임을 확인할 수 있다.

이는 시간차 테이블의 분포가 우측으로 편향(right skew)되어 발생한 결과이다. 해당 데이터에서는 첫번째 접속에서 두번째 접속까지의 시간이 매우 오래 걸린 유저가 일부 존재했을것이고, 이로인해 평균이 우측으로 치우쳐지는 현상이 발생한 것이다. 이 때문에 우리는 평균의 함정에 빠지지말고 4분위수도 꼼꼼히 확인하는 버릇이 필요하겠다.

'sql' 카테고리의 다른 글
| [sql] DAU3 (1) | 2024.03.19 |
|---|---|
| [sql] recursive CTE2 (0) | 2024.03.16 |
| [sql] DAU2 (0) | 2024.03.16 |
| [sql] DAU1 (0) | 2024.03.14 |
| [sql] recursive CTE (0) | 2024.02.17 |